本文翻译自How computers got shockingly good at recognizing images
2012年一篇里程碑式的论文改变了软件识别图片的方式。
现在,我可以打开谷歌相册,输入”海滩“,将会看到大量的海滩照片,这些都是我过去十年去过的地方。我从来没有给这些照片打过标签,取而代之的是,谷歌确认这些照片中的海滩,是通过这些照片里面的内容本身。这个看起来好像挺普通的功能,是运用了一项技术,叫做深度卷积神经网络。这个技术能让软件以一种复杂的方法”理解”这张图片,在这之前的技术是不可能做到的。
最近几年,研究人员发现随着他们建立深度网络,并使用大量的数据训练她们,软件的识别准确性越来越高了。这也创造了对计算机能力几乎无法满足的胃口,提升了那些GPU厂商的财富,例如Nvidia, AMD。谷歌几年以前,就开发了自己的定制神经网络芯片,其他公司也积极的跟进。
举个例子,在特斯拉,公司请到了深度学习专家Andrej Karpathy负责公司的自动驾驶项目。特斯拉正在开发自己的芯片,来为下一代的自动驾驶加速神经网络运算。另一个例子, 在苹果公司,A11和A12芯片在最近的iPhone的核心中都包含了“神经引擎”,用来加速神经网络运算。以此提供更好的图片和声音识别应用。
这篇文章中我与之交谈的专家,将当期深度学习热潮追溯到一篇特定的论文,绰号AlexNet,论文的主要作者Alex Krizhevsky.
“在我的印象中,2012年是里程碑式的一年,当AlexNet的论文出来以后”,机器学习的专家Sean Gerrish说。
回到2012年,在机器学习领域,深度神经网络其实是某种意义上的“回水”(我的理解是之前也有人研究,但是效果不理想),但是当时Krizhevsky和他的多伦多大学同事在一个图片识别竞赛上,高调的提交了一个作品,显著的比之前所有开发的都要精确。几乎隔夜,深度神经网络变成了图片领域的前沿技术。其他的研究人员利用这个技术很快的证明了图像识别准确性的进一步飞跃。
在这篇文章中,我们将深入的挖掘深度学习,我将要解释什么是神经网络,怎样训练他们,为什么他们需要如此多的计算能力。另外,我讲解释为什么一个特殊的神经网络类型–深度,卷积网络–在识别图片方面如此的优秀。不用担心,下面会有很多图片。
单神经元的简单例子
可能你对“神经网络”这个词,会感到有一丝的困惑。让我们以一个简单的例子开始吧。假设你想要用神经网络来决定一辆车是否能够通过红绿灯。一个单神经元的神经网络应该能完成这个任务。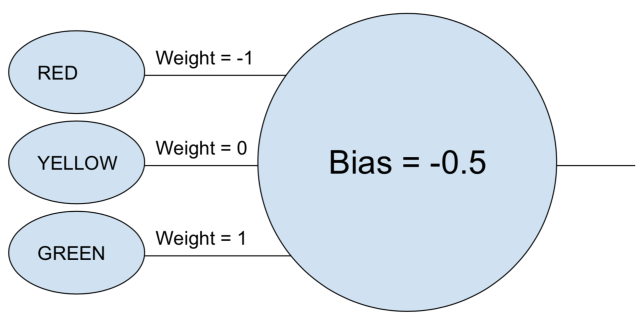
神经元取每次的输入(1 表示打开,0 表示关闭),和它关联的权重相乘,并将所有加权值相加。然后神经元再加上偏差值,得到的结果决定神经元“激活”的阈值。在这种情况下,如果输出值是正的,我们假设神经元已经”fired”(不知道怎么翻,有点像开火,点火,激活之类的意思吧),否则我们不会。这个神经元等于一下的不等式“绿 - 红 - 0.5 > 0”,如果这个不等式结果为true,意味着绿灯亮了,红灯灭了,车可以通过。
在真正的神经网络里面,人工的神经元要经过额外的一个步骤。在取加权值之和,再加上偏差值以后,要调用一个非线性的激活函数,一个比较流行的选择是sigmoid function, 一个S-shaped function总是产生(0,1)之间的值.
这个使用的激活函数不会改变我们这个简单的红绿灯模型的结果(除了我们需要使用0.5而不是0的阈值)。但是激活函数的非线性对于使神经网络能够模拟更复杂的函数至关重要,如果没有非线性激活函数,每个神经网络,不管多复杂,都可以简化其输入的线性组合。然而,一个线性函数是没法模拟复杂的真实世界的现象。非线性激活函数使得神经网络能够近似任何数学函数成为可能。
一个神经网络的例子
有很多的方法来近似函数,当然,神经网络的特殊之处在于我们知道如何使用一些微积分知识,大量的数据,还有大量的计算
能力来训练它们。我们可以构建一个通用的神经网络,而不是让一个人类程序员为了特定的任务而设计一个神经网络。通过观察大量带标签的示例,然后修改神经网络,以使它能够为已标记的示例产生尽可能多正确的标签。最后希望的结果是这个网络能够为哪些没在训练集里面的示例数据归纳,产生正确的标签。
到达这一点的过程在AlexNet之前就开始了。 1986年,三位研究人员发表了一篇关于反向传播的具有里程碑意义的论文,这种技术有助于使其在数学上易于训练复杂的神经网络。
为了有一个直观的了解,让我们看一下Michael Nielsen在他出色的在线深度学习教科书中展示的简单的神经网络。这个神经网络的目标是,取一个28*28像素的图片来表示一个手写的数字,正确的认出这个数字是0,1,2等等。
每张图片有28*28=784个输入值,每个值在0和1之间,代表像素的明暗程度。Nielsen构建了一个神经网络,像下面这样:
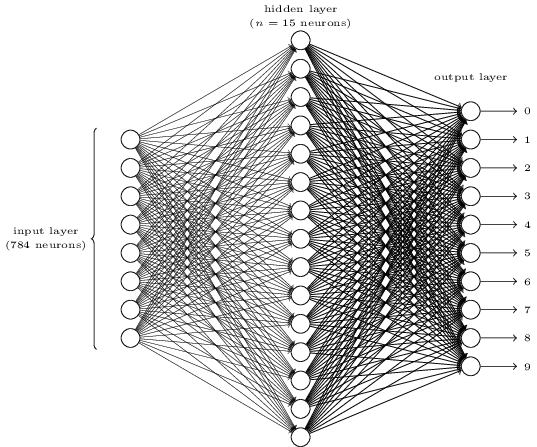
在这张图片中,中间和右边的每一个圆圈代表一个神经元,就像我们在上面章节看到的那样。每个神经元对其输入进行加权平均,添加偏差值,然后应用激活函数。注意左边的圆圈不是代表神经元,这些圆圈代表这个网络的输入值。虽然图像仅显示8个输入圆,但实际上有784个输入 - 输入图像中的每个像素一个。
右边的10个神经元表示为不同的数字“亮灯”,当输入的图片是手写的0,第一个神经元会“亮灯”,以此类推。
每个神经元从它之前层级的每个神经元获取输入,所以中间层中15个神经元中每个神经元都有784个输入值,这15个神经元中的每一个都有相对应784个输入值的权重参数,这就意味着这一层有单独的15x784=11760个权重参数。相似的,输出层包含10个神经元,每个神经元都从中间层的15个神经元中获取输入值,增加另外的15x10=150个权重参数,最重要的是,这个网络还有25个偏差值-这25个神经元每个都有。
训练这个神经网络
训练的目标是调整这11935个参数,最大化的使那个代表正确数字的,输出层的神经元亮灯。我们可以用那个很出名的数据集MNIST,它提供了60000个打了标签的28*28像素的图片:
This image shows 160 of the 60,000 images in the MNIST dataset.
Nielsen展示了如何训练这个网络,而仅仅使用了74行常规的Python代码–不需要特别的机器学习库。训练以选择这11935个参数和偏差开始。然后软件会查看示例图片,为每张图片完成以下两个处理步骤:
* 前馈步骤 给定输入图片和网络当前的参数,计算网络的输出值
* 反向传播步骤 计算结果偏离正确的输出值有多少,然后修改网络的参数,以略微提升在特定图片上的表现。
下面举个栗子,假设网络显示了这张图片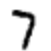
如果网络已经校准了,那网络中输出层代表”7“的神经元应该趋近于1,其他的应该趋近于0。但是出乎意料的是,当展示这张图片的时候,代表”0“的神经元趋近于0.8,这太高了!这个训练算法应该调整”0“的输入权重,使得下次能够让它趋于0。
为此,反向传播算法计算每个输入权重参数的误差梯度。作为一个衡量标准,对于给定的一个输入权重值的变化,所引起的输出值的误差变化的一个衡量标准,算法使用这个梯度来决定需要改变每个输入权重值的程度。梯度越大,需要改变的参数越多。
换句话说,训练程序”教”输出层的神经元,不要把注意力放在那些朝错误方向的输入值上(这里指中间层的神经元),而是多关注那些能够朝正确的输入值方向上。
该算法针对每个其他输出层神经元重复该步骤。它减少了“1”,“2”,“3”,“4”,“5”,“6”,“8”和“9”神经元(但不是“7”神经元)的输入权重将这些输出神经元的值向下推
plus: 文章没翻译完,一是太长了,二是这里的数学知识不太了解,等我入门机器学习以后,再继续翻译吧。有英文基础的建议看原文,虽然可能有些数学原理看不懂,但是还是能大概理解什么是机器学习。
Udacity免费课程
Google tensorflow 免费课程
原文地址 How computers got shockingly good at recognizing images